
La mise en place d’une bibliothèque virtuelle sur un site WordPress, monétisée via l’affiliation, représente une stratégie de contenu pertinente pour de nombreux secteurs. Ce dispositif permet non seulement d’enrichir l’offre éditoriale d’un site, mais aussi de générer des revenus passifs en recommandant des ouvrages thématiques. La réussite d’un tel projet repose sur une architecture technique solide, alliant la flexibilité de WordPress à la puissance des API externes pour automatiser la récupération des données et la génération des liens d’affiliation.
La démarche implique la création d’une structure de contenu dédiée, l’importation de données bibliographiques et l’interaction programmatique avec l’API d’Amazon pour enrichir les fiches produits. Il s’agit de concevoir un système capable de gérer un volume potentiellement important de références sans intervention manuelle fastidieuse, tout en offrant une expérience utilisateur fluide et optimisée pour le référencement naturel.
- Mettre en place une structure de contenu dédiée
- Définir les champs de données spécifiques aux livres
- Importer les données des livres en masse
- Automatiser l’enrichissement via l’API Amazon
- Construire la page de présentation d’un livre
- Créer la page principale de la bibliothèque
- Synthèse de la démarche technique
Mettre en place une structure de contenu dédiée
La première étape consiste à isoler les données relatives aux livres du reste du contenu du site. Pour ce faire, l’utilisation d’un Custom Post Type (CPT), ou type de publication personnalisé, est la méthode la plus propre et la plus évolutive. Nommer ce CPT « Livre » permet de créer une section distincte dans l’administration de WordPress, facilitant ainsi la gestion et l’organisation des références bibliographiques. Cette approche sépare logiquement les livres des articles de blog ou des pages, ce qui est bénéfique tant pour l’administration du site que pour le SEO, en permettant de structurer l’information de manière sémantique.
La création de ce CPT peut être réalisée à l’aide d’extensions reconnues. L’une des plus populaires, Advanced Custom Fields (ACF), offre désormais des fonctionnalités intégrées pour déclarer de nouveaux types de publications directement depuis son interface. La configuration est simple : il suffit de définir les libellés au singulier (« Livre ») et au pluriel (« Livres ») ainsi qu’une clé unique (par exemple, livre_amazon) qui servira d’identifiant technique dans le code et les requêtes futures.
Il est également judicieux d’associer des taxonomies personnalisées à ce CPT. Une taxonomie « Catégorie de livre », par exemple, permettra de classer les ouvrages par thématique (photographie, naturalisme, technique, etc.). Cette classification hiérarchique sera essentielle par la suite pour mettre en place des systèmes de filtres et de tri sur la page de la bibliothèque, améliorant ainsi la navigation pour l’utilisateur final.
Enfin, il convient de s’assurer que le CPT supporte les fonctionnalités de base de WordPress nécessaires, comme le titre, l’éditeur de contenu (Gutenberg), l’image mise en avant (qui servira pour la couverture du livre) et l’extrait. L’activation de l’extrait est particulièrement utile pour afficher des descriptions courtes dans les listes d’aperçu.
Définir les champs de données spécifiques aux livres
Une fois le CPT « Livre » créé, il est nécessaire de définir les champs qui accueilleront les informations spécifiques à chaque ouvrage. Les champs par défaut de WordPress (titre, contenu) sont insuffisants. C’est ici qu’ACF révèle toute sa puissance en permettant de créer un groupe de champs personnalisés qui sera rattaché exclusivement au CPT « Livre ». Ces champs structureront les données de manière précise et cohérente pour chaque entrée.
La création de ces champs doit être pensée en amont pour couvrir toutes les informations pertinentes. L’utilisation de types de champs simples comme « Texte » est souvent suffisante, surtout si les données sont importées en masse. Le contrôle de la saisie (par exemple, un champ « Numérique » pour l’année) devient moins prioritaire dans un contexte d’import automatisé, mais reste une option pour une saisie manuelle ultérieure.
Voici une liste des champs fondamentaux à créer pour une fiche livre complète :
- Descriptif court : Un champ de type texte pour un résumé concis.
- Auteur(s) : Pour le ou les noms des auteurs.
- Éditeur : Le nom de la maison d’édition.
- Année de parution : L’année de publication.
- Nombre de pages : Une donnée informative pour l’utilisateur.
- ISBN : Le numéro international normalisé du livre. Ce champ est le plus important, car il sert d’identifiant unique et de clé pour interroger l’API Amazon.
- Lien affilié : Un champ qui sera rempli ultérieurement, de manière automatisée, avec l’URL d’affiliation Amazon.
| Nom du champ (Libellé) | Identifiant technique (Nom) | Type de champ | Rôle principal |
| Descriptif court | descriptif_cours | Texte | Résumé pour les aperçus et la fiche livre. |
| Auteur(s) | auteur | Texte | Identification de l’auteur de l’ouvrage. |
| Éditeur | editeur | Texte | Identification de la maison d’édition. |
| Année de parution | annee_de_parution | Texte | Information temporelle sur la publication. |
| Nombre de pages | pages | Texte | Donnée quantitative sur le volume du livre. |
| ISBN | isbn | Texte | Clé d’identification unique pour l’API Amazon. |
| Lien affilié | lien_affilie | Texte | Stockage de l’URL de redirection monétisée. |
Une fois ce groupe de champs créé, il doit être assigné pour n’apparaître que sur les pages d’édition du type de publication « Livre ». Chaque nouvelle entrée de livre présentera alors cette interface de saisie structurée, prête à être remplie manuellement ou par import.
Importer les données des livres en masse
Alimenter manuellement une bibliothèque de plusieurs dizaines ou centaines de livres serait une tâche extrêmement chronophage. L’approche la plus efficiente est de préparer les données en amont dans un fichier tabulaire (Excel, CSV) pour ensuite les importer en une seule fois. La première étape consiste à obtenir cette liste. Des outils d’intelligence artificielle peuvent être sollicités pour générer rapidement une liste de livres thématiques avec les informations de base (titre, auteur, éditeur, ISBN).
Le prompt adressé à l’IA doit être précis, demandant une sortie tabulaire stricte, sans sauts de ligne ou formatage complexe, afin de garantir la compatibilité avec les outils d’import. La demande de l’ISBN est, encore une fois, fondamentale, car c’est cette donnée qui servira de pont vers l’écosystème Amazon. Une fois le fichier Excel ou CSV généré, il constitue la base de données brute à intégrer dans WordPress.
Pour l’importation, des extensions spécialisées sont nécessaires. Une solution comme WP Import Export Lite offre les fonctionnalités suffisantes pour cette opération. Le processus se déroule en plusieurs étapes : téléversement du fichier, sélection du CPT cible (« Livre ») et, surtout, le mappage des colonnes du fichier avec les champs de destination dans WordPress. Le titre du livre sera mappé avec le champ « Titre » du post, le résumé avec le champ « Contenu » ou « Extrait », et chaque autre information (auteur, éditeur, ISBN) avec le champ personnalisé ACF correspondant. Il est crucial d’utiliser l’identifiant technique du champ (par exemple auteur) lors du mappage pour que les données soient correctement enregistrées.
Automatiser l’enrichissement via l’API Amazon
À ce stade, les fiches livres sont créées dans WordPress, mais il manque deux éléments essentiels : la couverture du livre et le lien d’affiliation. Récupérer ces éléments manuellement pour chaque livre est inenvisageable. L’automatisation via l’API Product Advertising d’Amazon est la solution. Cela requiert un développement sur mesure, généralement sous la forme d’une petite extension (plugin) WordPress.
Le principe de ce plugin est le suivant : parcourir tous les CPT « Livre » qui possèdent un ISBN mais n’ont pas encore de lien d’affiliation. Pour chaque livre, le script exécute plusieurs actions :
- Nettoyage de l’ISBN : L’ISBN récupéré depuis le champ personnalisé est « sanitisé » pour supprimer les espaces ou tirets, afin qu’il soit conforme au format attendu par l’API.
- Premier appel API : Un premier appel est effectué pour convertir l’ISBN en ASIN (Amazon Standard Identification Number), l’identifiant unique des produits sur la plateforme Amazon.
- Second appel API : Une fois l’ASIN obtenu, un second appel permet de récupérer toutes les données du produit, notamment l’URL de l’image principale (la couverture) et de générer l’URL d’affiliation en y intégrant l’identifiant partenaire (le tag partenaire).
- Mise à jour dans WordPress : Le script télécharge l’image de la couverture, l’ajoute à la médiathèque WordPress, et l’associe comme « image mise en avant » au post du livre concerné. Simultanément, il enregistre le lien d’affiliation généré dans le champ personnalisé « lien_affilie ».
Ce processus peut être encapsulé dans une fonction déclenchable via un bouton dans l’interface d’administration de WordPress. Un traitement par lot (« batch ») permet de mettre à jour l’ensemble de la bibliothèque en une seule action, offrant un gain de productivité considérable.
Construire la page de présentation d’un livre
Avec des données complètes et structurées, il faut maintenant créer le modèle de page qui affichera les informations de chaque livre de manière attrayante et fonctionnelle. Plutôt que de modifier les fichiers PHP du thème, une approche moderne consiste à utiliser un constructeur de thème (Theme Builder), une fonctionnalité souvent incluse dans les thèmes avancés comme Astra Pro, couplé à des constructeurs de pages comme Spectra.
L’outil permet de créer un modèle de page unique (« single ») et de l’assigner dynamiquement à tous les posts de type « Livre ». À l’intérieur de ce modèle, on dispose des blocs qui peuvent puiser dans les données dynamiques du post affiché. Par exemple, un bloc « Titre » ira chercher le titre du livre, un bloc « Image à la une » affichera l’image mise en avant (la couverture), et des blocs de texte spécifiques iront chercher les valeurs des champs personnalisés (auteur, éditeur, ISBN, etc.) grâce à leur identifiant technique.
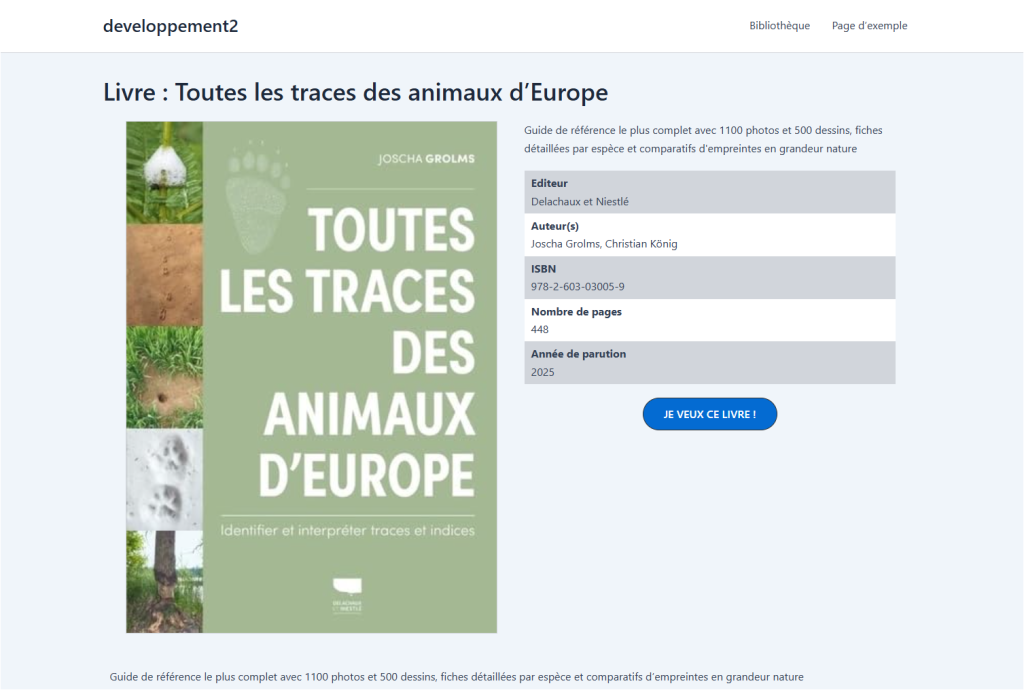
La mise en page peut être organisée en colonnes : la couverture à gauche, et les informations textuelles (résumé, tableau de caractéristiques, etc.) à droite. L’élément le plus important est le bouton d’appel à l’action (« Acheter sur Amazon », « Je veux ce livre »). Le lien de ce bouton doit être dynamiquement connecté au champ personnalisé « lien_affilie ». Ainsi, chaque page de livre affichera automatiquement le bon lien d’affiliation.
Créer la page principale de la bibliothèque
La dernière étape consiste à créer une page d’archive qui présente l’ensemble des livres sous forme de galerie. Un composant de type « Loop Builder » ou « Constructeur de boucle », fourni par des extensions comme Spectra, est idéal pour cette tâche. Cet outil permet de concevoir l’apparence d’un seul élément de la liste (un livre) et de répéter ce modèle pour tous les livres de la base de données.
La configuration de ce constructeur de boucle implique de spécifier la source des données : le CPT « Livre ». Ensuite, pour chaque item de la boucle, on peut définir les éléments à afficher : l’image mise en avant, le titre du livre, et éventuellement un champ personnalisé comme l’éditeur. Le titre de chaque livre doit bien entendu pointer vers sa page de présentation détaillée.
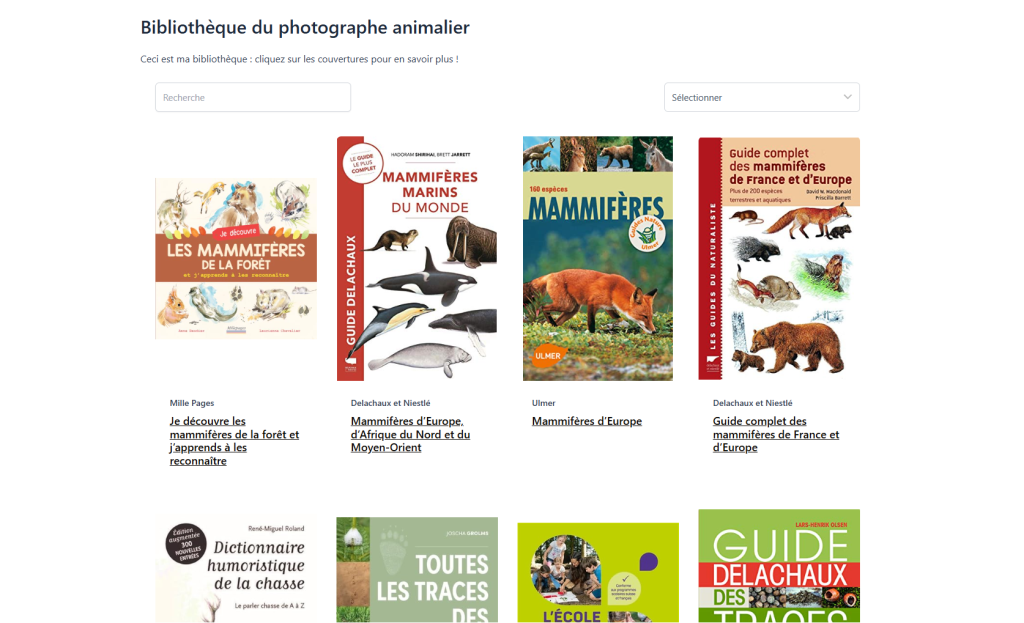
Pour améliorer l’expérience utilisateur, il est essentiel d’ajouter des fonctionnalités de filtrage et de recherche. Le « Loop Builder » peut être connecté aux taxonomies personnalisées créées précédemment. On peut ainsi ajouter une liste déroulante ou des boutons permettant de filtrer la bibliothèque par « Catégorie de livre ». Une barre de recherche peut également être intégrée pour permettre aux utilisateurs de trouver un livre par mot-clé dans le titre ou le contenu. Le résultat est une page de bibliothèque interactive, performante et facile à naviguer.
Synthèse de la démarche technique
La construction d’une bibliothèque affiliée performante sur WordPress est un projet qui combine judicieusement la structuration de contenu, l’automatisation par API et la conception dynamique de l’affichage. En suivant les étapes décrites, il est possible de mettre en place une plateforme robuste, capable de gérer un grand nombre de références avec un minimum d’effort de maintenance. L’architecture reposant sur les Custom Post Types et les champs personnalisés garantit une base saine et évolutive.
L’automatisation de la récupération des données via l’API Amazon représente le cœur de la productivité de ce système. Elle transforme une tâche manuelle fastidieuse en un processus exécutable en quelques clics. Couplée à la puissance des constructeurs de thèmes modernes, cette approche permet de créer des expériences utilisateur riches et cohérentes, tout en optimisant le potentiel de monétisation du contenu proposé. Le résultat final est une fonctionnalité à forte valeur ajoutée, tant pour le visiteur que pour l’administrateur du site.
Voir tous les articles de la catégorie WordPress




merci pour les détails, c’est une chouette approche qu’on peut imaginer à plein d’égards pour faire des listes d’objets sans devoir payer un plugin de comparateur de prix.