
La puissance d’un audit SEO technique réside dans la finesse de l’analyse. Un simple crawl, bien que fondamental, produit une masse de données brutes qu’il convient de contextualiser. La fonctionnalité de segmentation de l’outil de crawl Screaming Frog offre précisément cette capacité à catégoriser les URLs pour transformer une liste plate en une vision structurée et exploitable de l’architecture d’un site web. Cette approche permet d’isoler des typologies de pages spécifiques, de diagnostiquer des anomalies techniques ciblées et d’évaluer la pertinence du maillage interne avec une précision chirurgicale.
L’utilisation de segments permet de passer d’une observation globale à une analyse granulaire. En regroupant les pages par fonction (produits, catégories, articles, etc.), il devient possible de comparer leurs performances techniques, d’identifier des problèmes systémiques affectant un template de page particulier ou de valider que certaines sections du site, comme les facettes de navigation, sont bien exclues de l’indexation. La maîtrise de cette fonctionnalité est donc un prérequis pour mener des audits techniques approfondis et formuler des recommandations stratégiques pertinentes.
Principes fondamentaux de la segmentation dans Screaming Frog
La segmentation dans Screaming Frog repose sur un système de règles hiérarchisées permettant de classer chaque URL crawlée dans une catégorie définie. Le principe de fonctionnement est séquentiel : l’outil évalue chaque URL par rapport aux segments dans l’ordre où ils apparaissent dans la configuration. Dès qu’une URL correspond aux conditions d’un segment, elle lui est assignée et, si la configuration est bien pensée, elle est exclue des évaluations des segments suivants.
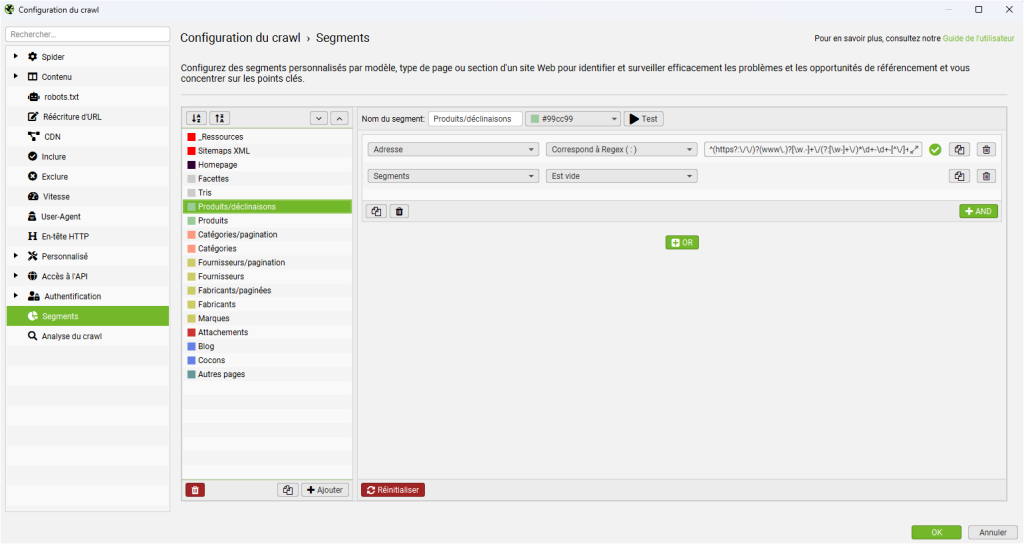
Cette notion de priorité est essentielle pour construire une segmentation logique et sans chevauchement. Par exemple, il est judicieux de placer en premier les segments identifiant les ressources non-HTML (images, CSS, JavaScript) afin de les isoler d’emblée de l’analyse des pages web. Ensuite, on peut définir les segments pour les pages spécifiques comme la page d’accueil, puis les modèles de pages plus généraux comme les fiches produits ou les catégories. Chaque segment est défini par une ou plusieurs conditions basées sur divers attributs de l’URL ou du contenu de la page.
Pour garantir que chaque URL n’appartienne qu’à un seul et unique segment, une pratique consiste à ajouter une condition systématique à chaque règle (sauf la première). Cette condition stipule que le champ « Segment » doit être vide. De cette manière, une URL déjà classée dans un segment prioritaire ne sera pas prise en compte par les règles suivantes, assurant ainsi des catégories exclusives. Cette méthode prévient la double comptabilisation et clarifie considérablement les rapports d’analyse, en permettant d’attribuer sans ambiguïté les problématiques techniques à des ensembles de pages bien définis.
Mise en œuvre par expressions régulières (Regex)
L’un des moyens les plus puissants et universels pour configurer les segments est l’utilisation des expressions régulières (Regex). Cette méthode permet de définir des motifs de recherche complexes pour faire correspondre des structures d’URLs spécifiques, ce qui est particulièrement efficace pour les plateformes e-commerce ou les CMS dont les schémas d’URL sont prévisibles et cohérents. La configuration s’effectue via le menu Configuration > Segments.
Pour illustrer ce processus, prenons l’exemple d’un site e-commerce. La structure de segmentation pourrait être la suivante :
- Ressources : Pour isoler tous les fichiers qui ne sont pas des pages HTML.
- Homepage : Pour identifier spécifiquement la page d’accueil.
- Produits : Pour cibler toutes les fiches produits.
- Catégories : Pour regrouper les pages de listage de produits.
- Autres pages : Un segment « fourre-tout » pour classer toutes les URLs restantes (pages de contact, mentions légales, blog, etc.).
La mise en œuvre technique repose sur la définition de motifs Regex précis pour chaque segment. Le tableau ci-dessous présente des exemples de configurations basiques qui peuvent être adaptées à la majorité des sites web.
| Catégorie | Titre | Expression régulière |
|---|---|---|
| Général | Ressources (autres que pages et sitemaps) | ^(https?:\/\/)(www\.)?[a-z0-9]+([\-\.]{1}[a-z0-9]+)*\.[a-z]{2,5}(:[0-9]{1,5})?(\/.*)?\.(svg|js|css|jpg|jpeg|png|gif|webp|avif)(\?.*)?$ |
| Général | Sitemaps XML | ^(https?:\/\/)(www\.)?[a-z0-9]+([\-\.]{1}[a-z0-9]+)*\.[a-z]{2,5}(:[0-9]{1,5})?(\/.*)?\.(xml)(\?.*)?$ |
| Général | Fichiers PDF | ^(https?:\/\/)(www\.)?[a-z0-9]+([\-\.]{1}[a-z0-9]+)*\.[a-z]{2,5}(:[0-9]{1,5})?(\/.*)?\.(pdf)(\?.*)?$ |
| Général | Homepage (avec sous-domaines) | ^(http:\/\/www\.|https:\/\/www\.|http:\/\/|https:\/\/)[a-z0-9]+(?:-[a-z0-9]+)*(?:\.[a-z0-9]+(?:-[a-z0-9]+)*)*\.(?:[a-z]{2,5})(?:\/)?(?:\?.*)?(?:#.*)?$ |
| Prestashop | Pages produit | ^(https?:\/\/)?(www\.)?[\w.-]+\/(?:[\w-]+\/)*\d+-[^\/]+\.html$ |
| Prestashop | Pages produit avec déclinaison | ^(https?:\/\/)?(www\.)?[\w.-]+\/(?:[\w-]+\/)*\d+-\d+-[^\/]+\.html$ |
| Prestashop | Pages catégorie | ^(https?:\/\/)?([a-z0-9]+(-[a-z0-9]+)*\.)+[a-z]{2,5}\/\d+-[^\/]+\/?$ |
| Prestashop | Page catégorie paginée | ^(https?:\/\/)?([a-z0-9]+(-[a-z0-9]+)*\.)+[a-z]{2,5}\/.*(\?(p|page)=\d+|\/#\/(p|page)-\d+)$ |
| Prestashop | Pages fournisseurs | ^(https?:\/\/)?([a-z0-9]+(-[a-z0-9]+)*\.)+[a-z]{2,5}\/\d+__[a-z0-9-]+\/?$ |
| Prestashop | Pages fournisseurs paginées | ^(https?:\/\/)?([a-z0-9]+(-[a-z0-9]+)*\.)+[a-z]{2,5}\/\d+__[a-z0-9-]+(\?(p|page)=\d+|\/#\/(p|page)-\d+)$ |
| Prestashop | Pages fabricants | ^(https?:\/\/)?([a-z0-9]+(-[a-z0-9]+)*\.)+[a-z]{2,5}\/\d+_[a-z0-9-]+\/?$ |
| Prestashop | Pages fabricants paginées | ^(https?:\/\/)?([a-z0-9]+(-[a-z0-9]+)*\.)+[a-z]{2,5}\/\d+_[a-z0-9-]+(\?(p|page)=\d+|\/#\/(p|page)-\d+)$ |
| Prestashop | Attachements | ^(https?:\/\/)?([a-z0-9]+(-[a-z0-9]+)*\.)+[a-z]{2,5}\/index\.php\?controller=attachment&id_attachment=\d+$ |
L’utilisation du préfixe underscore _ pour le segment des ressources est une convention utile qui permet de les trier et de les exclure plus facilement lors de l’exportation et de l’analyse des données. En appliquant systématiquement la condition Segment est vide, on s’assure que la segmentation est nette et que les totaux par segment sont fiables.
Technique avancée : la segmentation via l’extraction personnalisée
Lorsque les expressions régulières basées sur l’URL ne suffisent pas ou manquent de fiabilité, notamment sur des sites aux structures d’URL complexes ou hétérogènes, l’extraction personnalisée (Custom Extraction) offre une alternative redoutable. Cette technique consiste à extraire une information directement depuis le code source HTML des pages pour l’utiliser comme critère de segmentation. Il peut s’agir de la valeur d’un attribut id ou class sur la balise <body>, d’un fil d’Ariane, ou de tout autre marqueur unique à un type de page.
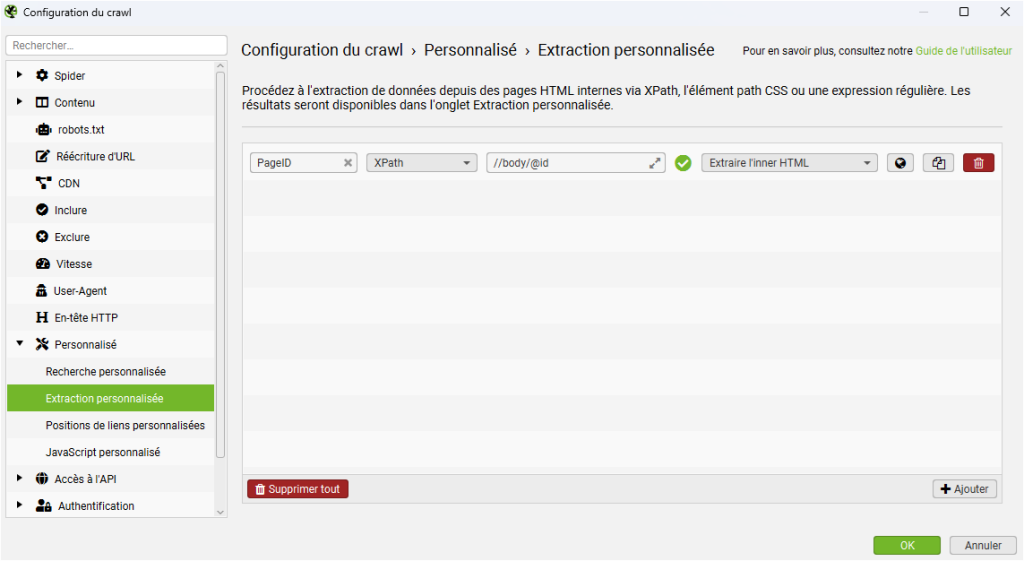
La mise en place se déroule en deux temps. D’abord, il faut configurer l’extraction via Configuration > Custom > Extraction. On y définit ce que l’outil doit extraire, par exemple l’attribut class de la balise <body>. Ensuite, après avoir relancé un crawl pour que Screaming Frog collecte ces nouvelles données, on peut utiliser les informations extraites dans la configuration des segments. Sur un site WordPress, par exemple, les articles de blog contiennent souvent la classe postid- dans la balise body, tandis que les pages contiennent page-id-.
Cette méthode permet d’automatiser et de fiabiliser l’identification des templates de page. Sur une boutique PrestaShop, la balise <body> contient souvent un attribut id qui identifie le type de page (id="product", id="category", id="manufacturer"). La configuration de la segmentation peut alors directement s’appuyer sur la valeur de cette extraction personnalisée. L’avantage majeur est la robustesse : même si les URLs changent suite à une refonte, tant que les marqueurs dans le code source restent les mêmes, la segmentation demeurera fonctionnelle et précise.
Visualiser et interpréter les données segmentées
Une fois la segmentation appliquée, l’intégralité des données du crawl peut être analysée sous ce nouveau prisme. Dans chaque onglet de l’interface (par exemple, Indexability, Response Codes, H1), un filtre déroulant « Segment » devient disponible. Il permet d’isoler les données pour une typologie de page spécifique. C’est ainsi que l’on peut rapidement vérifier si toutes les pages « Produit » ont un titre unique, si les pages « Facettes » sont bien en noindex, ou si des redirections existent au sein du segment « Autres pages », révélant parfois des erreurs de maillage interne, comme des liens pointant vers d’anciennes URLs.
La véritable puissance de cette approche se révèle lors de l’utilisation des outils de visualisation. Les diagrammes de crawl, notamment la « 3D Force-Directed Graph », utilisent un code couleur basé sur les segments. Cette représentation visuelle de l’architecture du site met en évidence la structure des liens internes et les relations entre les différentes typologies de pages. Une analyse visuelle permet de déceler rapidement plusieurs anomalies potentielles :
- Des grappes de pages d’une même couleur (segment) isolées du reste du site.
- Un manque de liens internes pointant vers des pages stratégiques (par exemple, des pages « Produit » recevant peu de jus de lien).
- Une prédominance de liens vers des pages à faible valeur SEO.
- Des connexions inattendues entre différents segments, signalant une structure de liens potentiellement confuse pour les utilisateurs et les moteurs de recherche.
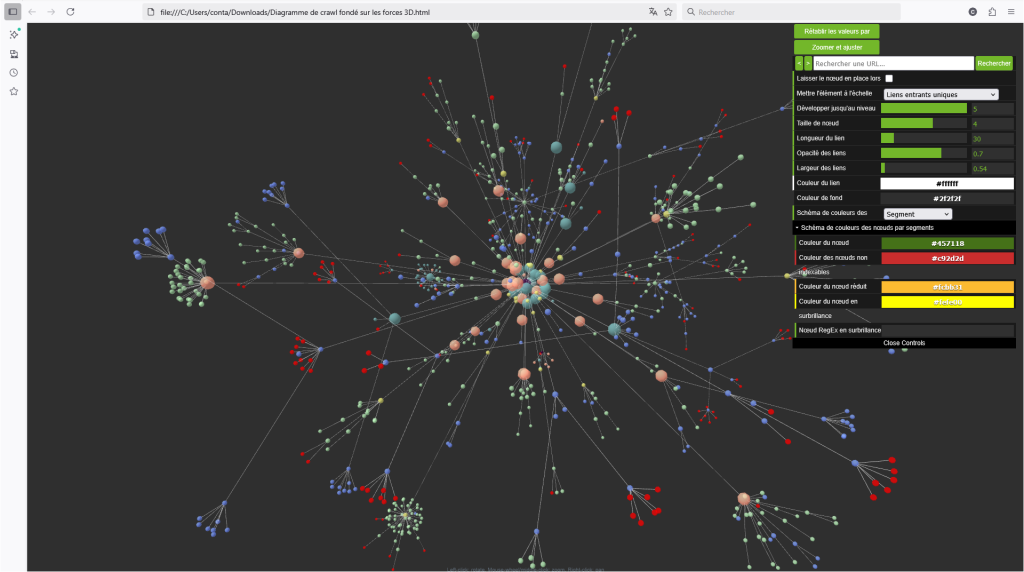
Cette analyse visuelle et chiffrée par segment offre une compréhension profonde de la manière dont le « link juice » (jus de lien) est distribué à travers le site et permet de formuler des recommandations précises pour l’optimisation du maillage interne.
Vers une optimisation des audits SEO par la segmentation
En conclusion, l’adoption d’une démarche de segmentation systématique dans Screaming Frog transcende l’audit technique standard. Elle transforme un volume de données potentiellement écrasant en un ensemble d’informations structurées, contextualisées et directement actionnables. La capacité à isoler, comparer et analyser des groupes de pages homogènes est un levier d’efficacité majeur pour le consultant SEO.
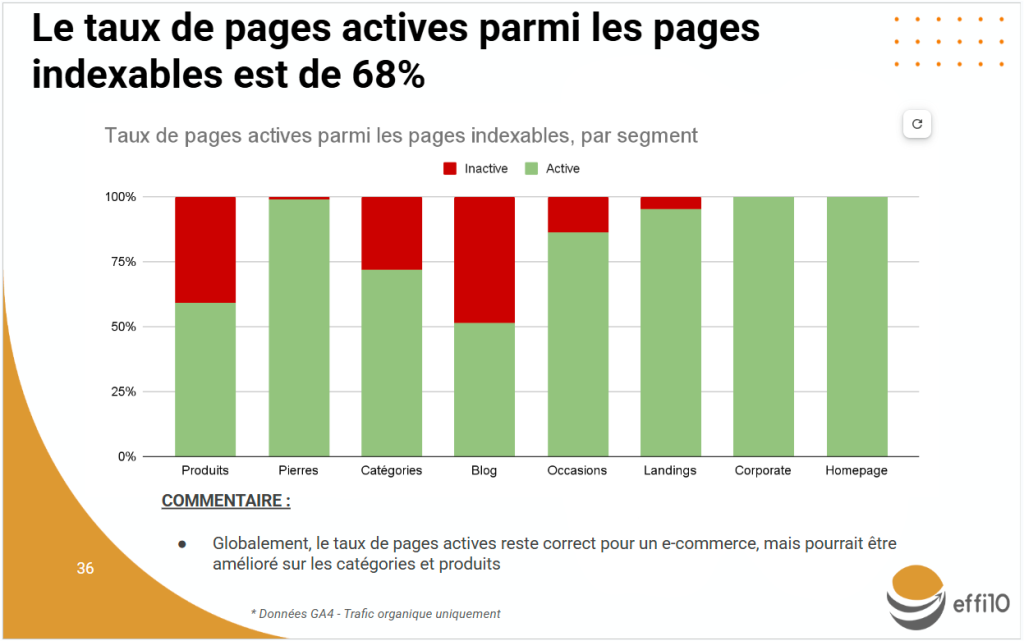
Cette méthode affine le diagnostic en localisant avec précision l’origine des problèmes techniques et en révélant des schémas qui resteraient invisibles dans une analyse globale. Que ce soit par l’utilisation flexible des expressions régulières ou la précision chirurgicale de l’extraction personnalisée, la segmentation est une discipline qui confère une profondeur analytique supérieure. Elle ne doit pas être considérée comme une simple fonctionnalité, mais comme un pilier méthodologique au cœur de tout audit SEO technique rigoureux, visant à optimiser durablement la performance d’un site web.
Voir tous les articles de la catégorie Techniques de référencement



