L’évaluation de l’importance et de la pertinence d’une page web a radicalement évolué depuis les débuts des moteurs de recherche. Le principe fondateur, qui a déplacé l’analyse de la pertinence du simple contenu textuel vers une mesure objective basée sur la structure des liens, repose sur l’idée qu’un hyperlien constitue une forme de recommandation. La valeur de cette recommandation dépend directement de l’importance de la page émettrice.
Cette approche a donné naissance à une métaphore conceptuelle puissante : celle du « surfeur » dont le comportement modélise la distribution de l’autorité à travers le graphe du web. L’évolution de cet algorithme peut être appréhendée à travers la transformation de ce surfeur. Initialement purement aléatoire, il est devenu « raisonnable » en intégrant des notions de qualité et de confiance pour lutter contre les manipulations. Finalement, il est devenu « thématique », adaptant son parcours à la sémantique des liens et à l’intention spécifique de l’utilisateur, marquant le passage d’une autorité statique à une pertinence dynamique et contextuelle.
- Qu’est-ce que le PageRank ?
- Évolution chronologique des briques algorithmiques du PageRank
- Les évolutions algorithmiques du PageRank en détail
- Le modèle du Surfeur raisonnable : vers la confiance et la qualité
- Le modèle du Surfeur thématique : la sémantique au coeur de l’algorithme
- Synthèse de l’évolution des modèles de parcours de lien
- Implications techniques et intégration dans les moteurs de recherche
- De l’autorité objective à la pertinence contextuelle
Qu’est-ce que le PageRank ?
L’algorithme du PageRank a introduit une méthode révolutionnaire pour attribuer un rang d’importance objectif aux pages d’une base de données hyperliée. Son principe fondamental s’éloigne du simple comptage de liens entrants pour proposer une définition récursive de l’importance : la valeur d’une page est déterminée par l’importance cumulée des pages qui pointent vers elle. Ainsi, un lien provenant d’une page à forte autorité a significativement plus de poids qu’un lien émanant d’une page de faible importance.
Le calcul de ce rang est de nature itérative. La formule de base pour une page A peut être exprimée comme suit :
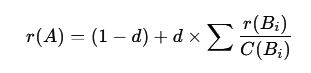
Dans cette équation, r(A) est le rang de la page A, les Bi sont les pages qui pointent vers A, r(Bi) est leur rang respectif, et C(Bi) est le nombre de liens sortants de chaque page Bi. Le facteur d’amortissement, noté d (généralement fixé autour de 0.85), représente la probabilité qu’un utilisateur continue sa navigation en suivant les liens. L’algorithme démarre avec une distribution de rang uniforme et applique la formule de manière répétée jusqu’à la convergence des valeurs, ce qui correspond mathématiquement au vecteur propre principal de la matrice de liens du Web.
Pour conceptualiser ce flux d’autorité, le modèle du Surfeur aléatoire a été introduit. Il simule un utilisateur qui, à chaque page, a deux possibilités : soit suivre l’un des liens sortants avec une probabilité , soit cesser de suivre les liens et sauter vers n’importe quelle autre page du Web avec une probabilité
 . Ce saut aléatoire garantit qu’aucune page, même isolée, ne soit privée de rang et assure une distribution de l’autorité sur l’ensemble du graphe. Le rang d’une page correspond ainsi à la probabilité de présence à l’état stable de ce surfeur après une longue navigation.
. Ce saut aléatoire garantit qu’aucune page, même isolée, ne soit privée de rang et assure une distribution de l’autorité sur l’ensemble du graphe. Le rang d’une page correspond ainsi à la probabilité de présence à l’état stable de ce surfeur après une longue navigation.
Évolution chronologique des briques algorithmiques du PageRank
L’algorithme du PageRank, bien que conceptuellement stable dans son principe fondateur, n’est pas une entité monolithique. Son application et les briques technologiques qui le complètent ont connu une évolution constante, en réponse directe aux transformations du web et aux tentatives de manipulation de ses résultats. Cette chronologie met en lumière une sophistication croissante, passant d’un calcul structurel pur à une intégration profonde au sein d’écosystèmes algorithmiques complexes.
À sa création à la fin des années 1990, le PageRank récursif constituait la brique centrale. L’enjeu était d’apporter un classement pertinent à un web en pleine expansion mais chaotique. Le modèle du « Surfeur Aléatoire » offrait une solution mathématique élégante pour quantifier l’autorité de manière objective et scalable. Durant cette première ère, l’algorithme fonctionnait de manière relativement isolée, sa valeur étant principalement déterminée par la structure brute du graphe des liens.
Le début des années 2000 a marqué un tournant, avec l’émergence du référencement naturel et, par conséquent, des stratégies de manipulation. Pour contrer ces phénomènes, de nouvelles briques algorithmiques ont été développées. Le concept de TrustRank (vers 2004) a introduit la notion de « propagation de la confiance » depuis un ensemble de sites sources fiables. Parallèlement, le Topic-Sensitive PageRank est apparu comme une première tentative de contextualisation, en calculant non pas un, mais plusieurs scores de PageRank pour une même page, chacun correspondant à une thématique spécifique (ex: sports, santé, finance). L’introduction de l’attribut rel="nofollow" en 2005 a également fourni un outil technique permettant de mieux contrôler les flux de PageRank, en signalant les liens ne devant pas être considérés comme un vote de confiance.
L’année 2009 a marqué un changement substantiel dans la manière dont l’algorithme traite l’attribut nofollow. Cette révision visait à neutraliser les optimisations de type PageRank sculpting. En conséquence, la transmission de l’autorité a été modifiée : un lien nofollow est désormais inclus dans le calcul de la division du PageRank, mais sa part d’autorité est perdue plutôt que d’être réaffectée aux autres hyperliens de la page.
La période post-2010 a vu l’intégration progressive du PageRank comme un signal parmi des centaines d’autres au sein de systèmes de machine learning. Avec l’avènement d’algorithmes comme RankBrain puis des modèles de traitement du langage naturel (NLP) tels que BERT, le rôle du PageRank a été redéfini. Il n’est plus le facteur de classement prédominant, mais une brique fondamentale qui informe les modèles d’intelligence artificielle sur l’autorité et la fiabilité des entités présentes sur le web. La fin de l’affichage public du score PageRank en 2016 a symbolisé ce changement : la valeur n’est plus dans le score brut, mais dans son utilisation comme un signal de confiance au service d’une compréhension plus holistique de la pertinence et de l’intention de l’utilisateur.
Les évolutions algorithmiques du PageRank en détail
Le modèle initial du Surfeur aléatoire, bien que novateur, présentait des vulnérabilités. Sa nature purement mathématique et structurelle le rendait sensible aux techniques de manipulation, notamment les stratégies de création massive de liens artificiels connues sous le nom de link farms. Ces réseaux de sites, conçus dans le seul but de s’échanger des liens, pouvaient gonfler artificiellement le PageRank de certaines pages, dégradant ainsi la qualité et la pertinence des résultats de recherche.

Face à ces défis, il est devenu nécessaire de faire évoluer l’algorithme au-delà d’un modèle purement stochastique. L’objectif était de développer des systèmes capables d’intégrer des signaux de qualité et de confiance externes, afin de mieux distinguer les liens légitimes des liens manipulatoires. Cette évolution a conduit à l’émergence de modèles plus sophistiqués, incarnés par la figure conceptuelle d’un « surfeur raisonnable », dont le comportement n’est plus entièrement aléatoire mais guidé par des indicateurs de fiabilité.
Le modèle du Surfeur raisonnable : vers la confiance et la qualité
L’archétype du « Surfeur raisonnable » marque une étape décisive en introduisant des jugements de qualité dans le processus de classement. Son comportement n’est plus purement aléatoire mais influencé par des facteurs externes visant à identifier et à valoriser la fiabilité. Deux approches principales illustrent cette évolution.
La première approche consiste à guider le surfeur en utilisant des jugements de qualité. Le modèle ne se base plus sur une unique matrice de liens, mais sur une combinaison linéaire de plusieurs matrices. Parmi celles-ci, on trouve des matrices attractives, qui identifient des pages de haute qualité (validées par des experts ou des algorithmes), et des matrices non-attractives, qui signalent des contenus à éviter. Le surfeur est alors fortement incité à « sauter » vers les pages désirables et à s’éloigner des pages indésirables, rendant son parcours plus qualitatif.
La seconde approche, souvent associée au concept de TrustRank, se fonde sur la propagation de la confiance à partir de sources fiables.
- L’algorithme part d’un ensemble restreint de pages de confiance (« seed pages »), sélectionnées manuellement pour leur autorité et leur fiabilité (sites universitaires, portails institutionnels, etc.).
- L’importance d’une page n’est plus calculée comme une probabilité de visite, mais comme sa « distance » par rapport à ces sources de confiance. Une page est d’autant plus fiable qu’elle est « proche » d’une page « seed ».
- La « longueur » d’un lien est calculée de manière à pénaliser les caractéristiques associées au spam. Par exemple, la longueur d’un lien augmente avec le nombre de liens sortants de la page source. Ce mécanisme rend les chemins passant par des pages manipulatrices plus « longs » et donc moins influents. Ce surfeur est prudent, il explore le web en partant de territoires connus et fiables.
Le modèle du Surfeur thématique : la sémantique au coeur de l’algorithme
La dernière grande évolution du modèle est celle du « Surfeur thématique », qui personnalise le classement en fonction du contexte de la recherche et de la signification des liens. Cette approche reconnaît que tous les liens ne sont pas équivalents et que leur valeur dépend de l’intention de l’utilisateur. Elle s’inscrit dans le cadre du Web Sémantique, où les liens ne sont plus de simples connecteurs, mais des relations qualifiées avec une signification explicite comme « cite ce document », « est l’auteur de » ou « est publié par ».
Dans ce paradigme, le graphe du Web est décomposé en multiples sous-graphes thématiques, chacun correspondant à un type de lien sémantique spécifique. L’algorithme calcule un rang distinct pour une page au sein de chaque sous-graphe. Une page ne possède donc plus un score unique, mais un « vecteur de rang » dont chaque composante représente son autorité dans un contexte sémantique donné. Par exemple, un article scientifique peut avoir un rang élevé dans le sous-graphe des « citations » mais un rang plus faible dans celui des « publications commerciales ».
La personnalisation intervient au moment de la requête de l’utilisateur. Celui-ci fournit, implicitement ou explicitement, un vecteur d’intérêt qui attribue un poids aux différents types de liens sémantiques. Pour une recherche académique, un utilisateur valorisera davantage les liens de type « citation » que les liens de type « auteur ». Le score de pertinence final est alors calculé en combinant le vecteur de rang de la page avec le vecteur d’intérêt de l’utilisateur, souvent par une mesure de similarité cosinus. Le classement devient ainsi dynamique, contextuel et centré sur l’utilisateur, reflétant une pertinence spécifique plutôt qu’une importance universelle.
Synthèse de l’évolution des modèles de parcours de lien
La transition du Surfeur aléatoire au Surfeur thématique illustre une complexification croissante des algorithmes, visant à mieux interpréter la structure du web et l’intention de l’utilisateur. Le point de départ était un modèle universel et statique, où chaque lien était un vote de valeur égale, diluée par le nombre total de liens sortants. L’évolution a introduit des notions de confiance et de qualité pour contrer les abus, puis des notions de sémantique et de contexte pour affiner la pertinence.
Le tableau suivant synthétise les caractéristiques distinctives de chaque modèle conceptuel, mettant en lumière cette trajectoire d’un calcul d’autorité brute vers une évaluation de pertinence personnalisée.
| Caractéristique | PageRank (Surfeur Aléatoire) | Classement par Confiance (Surfeur Raisonnable) | Classement Sémantique (Surfeur Thématique) |
| Principe Clé | Importance basée sur la structure globale des liens. | Importance basée sur la proximité à des sources de confiance. | Pertinence basée sur la sémantique des liens et l’intérêt de l’utilisateur. |
| Nature du Lien | Uniforme et non qualifié (<a href>). | Uniforme, mais la qualité du chemin est évaluée. | Sémantique et typé (ex: « cite », « auteur de »). |
| Point de Départ | Distribution uniforme sur l’ensemble du graphe web. | Ensemble restreint de « pages de confiance » (seed pages). | Pages correspondant à la requête textuelle. |
| Mécanisme | Marche aléatoire avec sauts uniformes. | Calcul de la distance la plus courte depuis les sources fiables. | Navigation pondérée selon un vecteur d’intérêt thématique. |
| Résultat | Un rang d’importance statique et universel. | Un score de confiance, efficace contre le spam. | Un score de pertinence dynamique et personnalisé. |
Implications techniques et intégration dans les moteurs de recherche
Il convient de noter que ce score structurel, qu’il soit issu du PageRank ou de ses descendants, ne constitue qu’une des nombreuses composantes utilisées par un moteur de recherche pour classer les documents. Le processus global commence par une phase d’exploration (crawling) et d’indexation, durant laquelle le contenu textuel et la structure des liens de milliards de pages sont analysés et stockés.
Lorsqu’un utilisateur soumet une requête, le moteur identifie d’abord un ensemble de pages pertinentes sur le plan textuel. Cette correspondance prend en compte le contenu de la page, ses balises de titre, mais aussi des signaux externes puissants comme le texte d’ancre (« anchor text ») des liens qui pointent vers elle. C’est seulement ensuite que la liste des documents pertinents est triée. Une fonction de classement complexe combine alors le score de pertinence textuelle avec le score d’importance structurelle pré-calculé. Les pages qui excellent sur ces deux axes sont celles qui apparaissent en tête des résultats.
De l’autorité objective à la pertinence contextuelle
L’introduction de l’algorithme du PageRank a marqué un tournant fondamental dans l’histoire de la recherche d’information, en établissant que la connectivité était une mesure fiable de l’autorité. La métamorphose de la figure du « surfeur » illustre parfaitement la trajectoire de sophistication de ce principe. Parti d’un modèle probabiliste simple et universel, il a évolué pour intégrer des notions de qualité et de fiabilité, offrant des résultats plus pertinents et plus sûrs.
L’aboutissement de cette évolution, le surfeur thématique, consacre le passage définitif d’une notion d’importance objective et statique à une mesure de pertinence dynamique, personnalisée et contextuelle. Cette trajectoire reflète la quête continue pour affiner la compréhension non seulement de la structure du web, mais aussi de la richesse sémantique des données et des intentions précises qui animent chaque recherche d’information.

Voir tous les articles de la catégorie Techniques de référencement



